

By Yuchen Fama, Chris Sosa, Tony Shakib, Dušan Veljko,
SDG: The Hidden Accelerator in the Age of Small-but-Mighty LLMs
A revolution quietly unfolds in the shadow of DeepSeek, multi-agent compute and AI PCs. The next frontier of AI deployment isn’t about bigger models—it’s about smarter orchestration: optimizing resources with intelligent compute and surgical precision to unleash maximum potential from minimal hardware.
Software Defined GPU

Fractional GPU memory and computing are the essential backbones of fine-grained dynamic optimization. In this blog, we share our methodology and results using SDG to optimize memory and compute resource allocation with multiple models running concurrently on AMD MI300X GPUs, and benchmark tests demonstrating substantial gains in model performance and resource utilization.
AMD MI300 Key Facts
- HBM directly on chip (as compared to Nvidia’s cards where the HBM is on separate chips on the card) which means higher memory bandwidth. This matters a lot for AI workloads because you can load tensors faster and speed up memory-compute especially on concurrent operations. Estimates are 5.3TB/s for the MI300 vs 2-3 TB/S for the H100.
- MI300A is an APU with both a GPU and a CPU. This unified memory architecture reduces data copying overhead between CPU and GPU, which is a common problem:
- Frameworks like vLLM that dynamically swap KV cache between GPU and CPU memory
- Offloading GPU to CPU memory causes significant overhead
- MI300x has 192 GB of HBM3 memory, and MI300A has 128GB of memory (H100 has 80GB): Easily accommodates multiple large model weights, intermediate activations, and fine-tuning data.
- MI300 series uses RDMA protocol, meaning GPU-GPU memory transfer doesn’t involve CPU – great for large LLM full training runs.
- AMD supports flexible memory and compute slicing, so it allows better control of software-defined GPUs
Current GPU Sharing Technologies
MIG’s Boundaries
MIG provides good isolation as a hardware partition, but lacks flexibility for elastic and on-demand resources needed from AI workloads:
- Hardware-limited to A100/H100 datacenter GPUs
- Fixed partition configurations with predefined resource ratios
- Difficult to reconfigure dynamically without complete workload disruption
- Maximum of seven instances regardless of workload requirements
Time Slicing’s Performance Tax
Time slicing is very flexible but lacks isolation
- Memory allocation contention causing performance degradations between applications
- Heavy context switching overhead with latency spikes
- Unpredictable execution windows creating inconsistent performance
- Inefficient resource allocation across different workload types
SDG: Combining the Best of Both Worlds
Both approaches force painful tradeoffs between flexibility/adaptability AI workload demands, and performance isolation/predictability for production serving. SDG combines the best of both worlds
- Allow users to request GPUs with arbitrary memory sizes
- Designed to work with different vendors and versions of GPUs and accelerators
- Leverage Kubernetes DRA for GPU orchestration and resource management
- Industry-leading memory isolation, flexibility, and support of dynamic config
- Non-intrusive with minimal config needed – users don’t need to adapt programming interfaces
Compared to other existing alternatives, such as GPU sharing feature from KAI (recently open-sourced by Nvidia after Run.ai’s acquisition), SDG provides strong performance isolation to prevent the “noisy neighbor” problem and ensures the QoS in a multi-tenant environment, and can scale to thousand-node clusters.
With the rapid growth of Agentic and RAG workflows with tightly coupled models’ collaboration, flexible, robust, and scalable GPU sharing in Kubernetes environments is one of the most important foundational building blocks for AI-first infrastructure.
Now let’s look at the case study and benchmark results:
Benchmark and Results: Smart Memory and Compute Slicing
We designed a real-world scenario running two distinct types of AI workloads. There are 2 GPUs (MI300x).
- Memory-intensive task: Document summarization using Llama 70B
- Compute-intensive task: Complex reasoning with DeepSeek Qwen 1.5B solving Einstein puzzle.
These models represent the common mixed workload scenario where different AI applications with varying resource profiles must coexist on shared infrastructure.
Test Set Up


Benchmark Methodology and Results
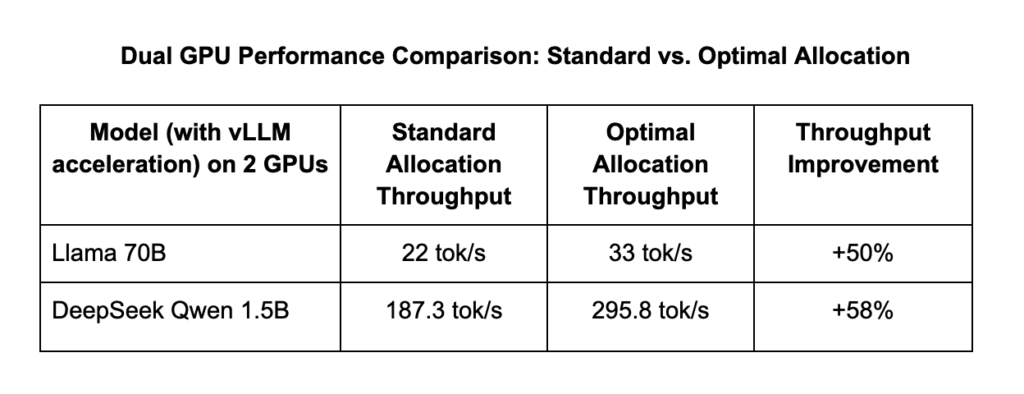
We tested two GPU resource allocation strategies for running Llama 70B and DeepSeek Qwen 1.5B models concurrently, measuring inference throughput in tokens per second.
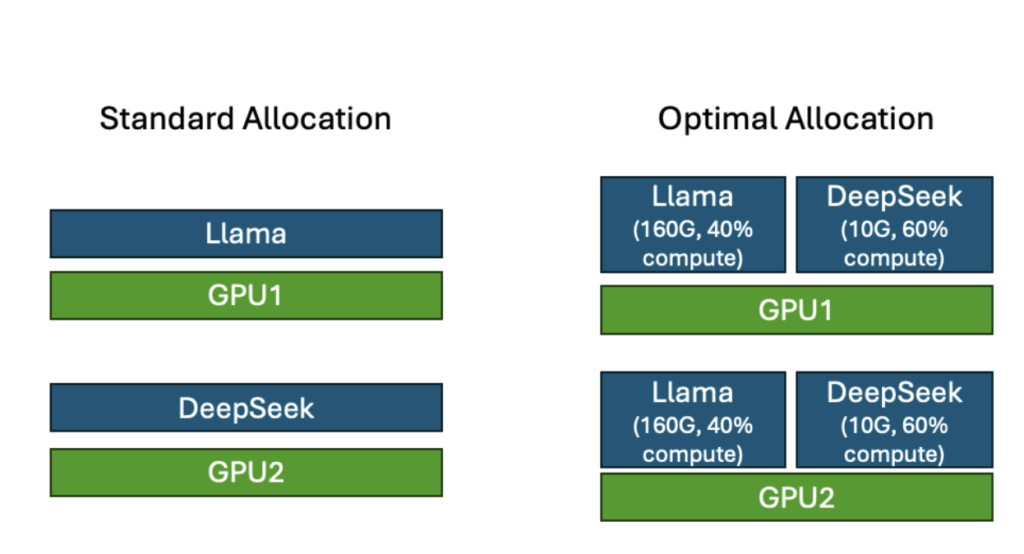
Standard Allocation: Dedicating one GPU to one model
- No GPU sharing – each model runs on a dedicated GPU
- Single GPU: Each model runs exclusively on one GPU sequentially
- Two GPUs: each GPU is dedicated to each model
Optimal Allocation: Partitioning based on Models’ Memory and CU Resource Needs
- Memory allocation: 160GB for Llama 70B, 10GB for DeepSeek Qwen 1.5B
- Compute unit allocation: 40% to Llama 70B, 60% to DeepSeek Qwen 1.5B
- Models run in parallel on shared resources (either sharing a single GPU or two GPUs)


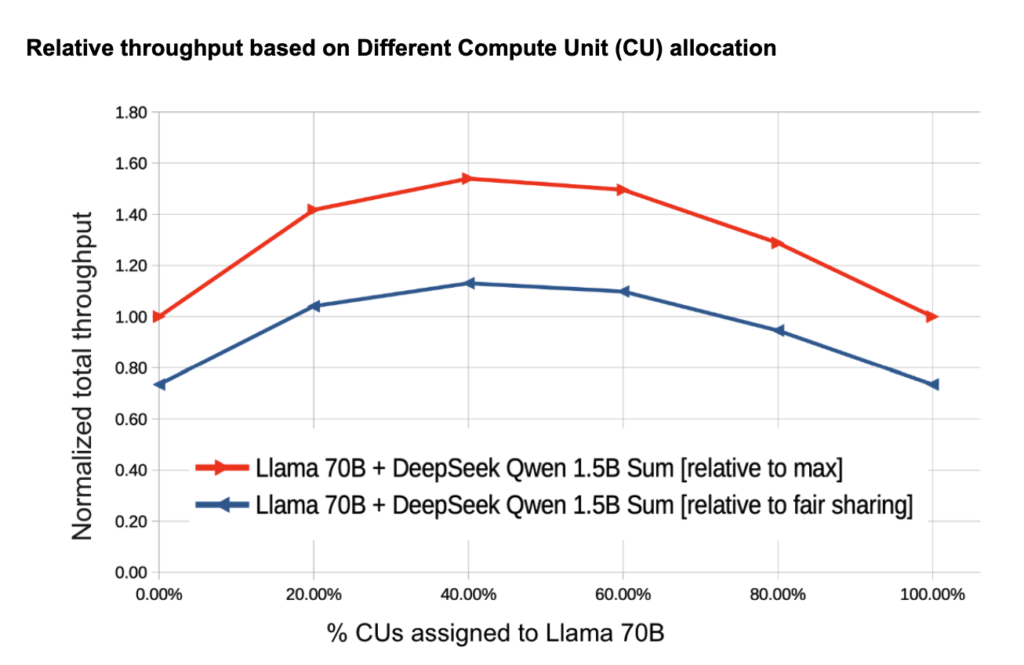

The x-axis represents the percentage of CUs assigned to Llama 70B (with DeepSeek Qwen getting the remainder). The y-axis shows relative throughput measured in two ways:
- Red line: Total throughput relative to maximum possible throughput (The model is exclusively running on the GPU with no interference from the others)
- Blue line: Total throughput relative to fair sharing ( time-slice allocation running processes in parallel without exclusively assigning CU).
The throughput is calculated using normalized values to ensure fair comparison:
- Each model’s throughput is expressed as a percentage of its maximum possible throughput
- These percentages are then summed up
For example, with 40%/60% CU allocation (Llama/DeepSeek):
- Llama 70B: 16.5 tok/s (75% of its 22 tok/s maximum on a dedicated GPU)
- DeepSeek Qwen: 147.9 tok/s (79% of its 187.3 tok/s maximum on a dedicated GPU)
- Combined relative performance: 75% + 79% = 154%
This approach prevents the higher absolute throughput of DeepSeek from dominating the analysis.
Key Insights and Takeaways
- Smart partition for both memory vs. compute matters: The optimal allocation point occurs at around 40% CU for Llama 70B and 60% for DeepSeek Qwen. With two GPUs, this optimal allocation would deliver ≥150% performance compared to running each model on a dedicated GPU
- Resource Profiles Matter: The performance curve shows that different AI tasks have different resource utilization patterns. SDG’s workload-aware memory and compute slicing tailored to each model’s resource needs find the “sweet spot” for the optimal resource allocation.
- Node Level Scheduling of Multiple GPUs Matters: Tightly coupled AI tasks such as multi-agent workflows, video intelligence (e.g. detection+tracking) and call center AI assistant (audio->text->audio) often need to be colocated using shared resources. Their resource profile, traffic pattern, and dependency/ordering require node-level scheduling.
Common Memory vs. Compute-Bound AI Workflows
AI workflows often have different memory vs. compute bottlenecks, and below are some common examples:
Memory-Bound AI Workflows:
- LLM Token Generation: The autoregressive generation phase of LLM inference, where the model produces one token at a time
- Retrieval-Augmented Generation (RAG): Loading and processing large vector databases for context retrieval
- Vision-Language Models (VLM): Processing high-resolution images with multi-modal models
- Long-Context LLMs: Models processing documents with extended context windows (32K+ tokens)
- Graph Neural Networks: Processing large interconnected data structures
Compute-Bound AI Workflows:
- LLM Prompt Processing: The initial parallelizable phase of inference where the prompt is processed
- Computer Vision Object Detection: Real-time inference on video streams (YOLO, SSD)
- Embedding Generation: Creating vector representations of text or images
- Fine-tuning Small Models: Training procedures for specialized models with limited parameters
- Reinforcement Learning: Policy optimization and environment simulation
Many real-world AI applications involve both workloads in sequence or parallel, making intelligent resource orchestration particularly valuable.
Conclusion
The throughput improvement can be directly translated into GPU cost savings – customers only need ~50-60% of the GPUs to achieve the same performance.
Our testing confirms that intelligent resource orchestration with workload-aware memory and compute slicing delivers substantial performance gains when running mixed AI workloads. Organizations can extract significantly more value from their existing GPU infrastructure by understanding and adapting to the unique resource profiles of different models.
Today’s agent-based architectures don’t demand massive compute—they demand intelligent compute. The days of static GPU allocation are behind us – adaptive, intelligent orchestration is the key to maximizing AI infrastructure efficiency. Sign up for our early access program https://exostellar.io/gpu-optimizer-early-access/ and let us know your feedback!
